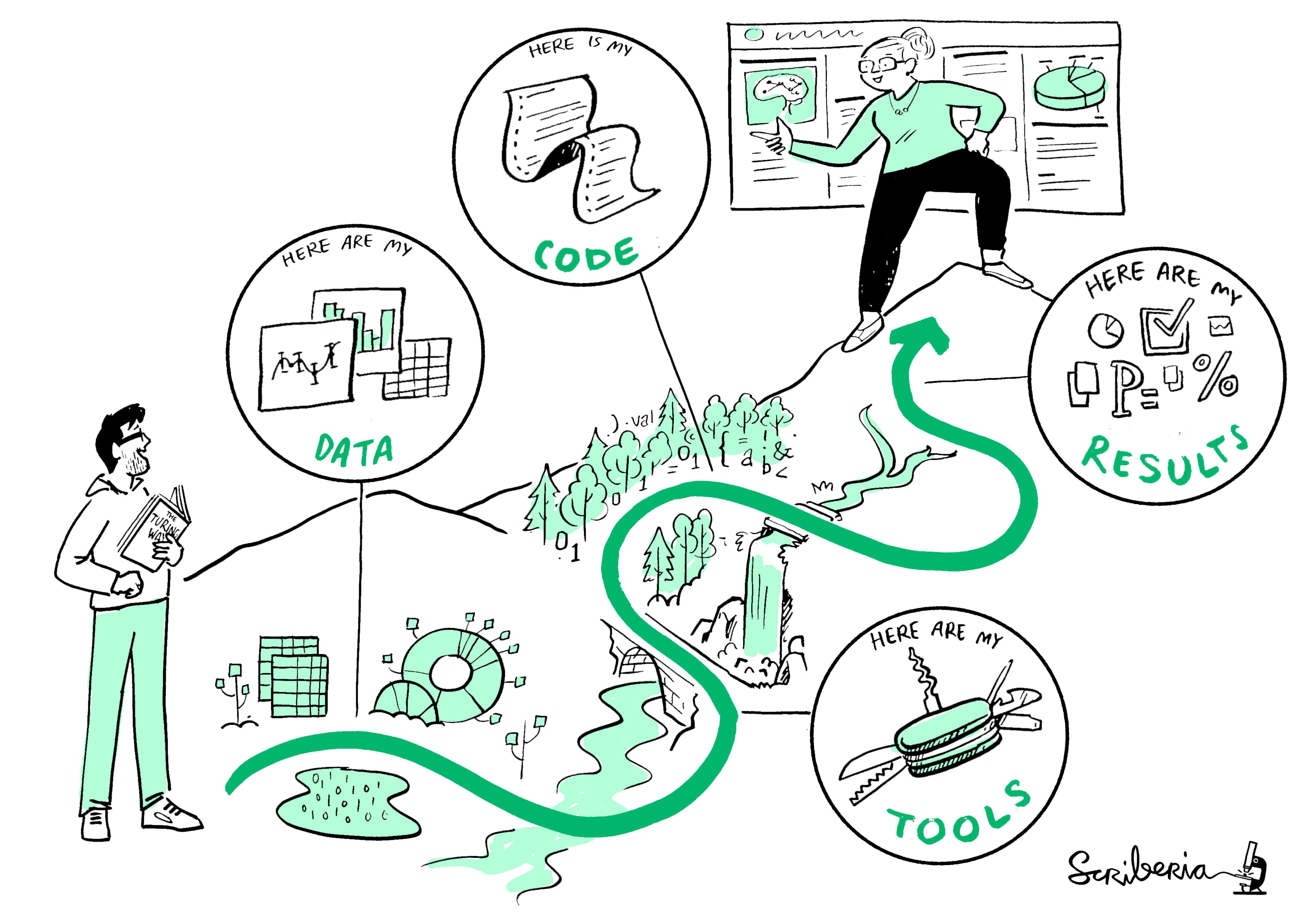
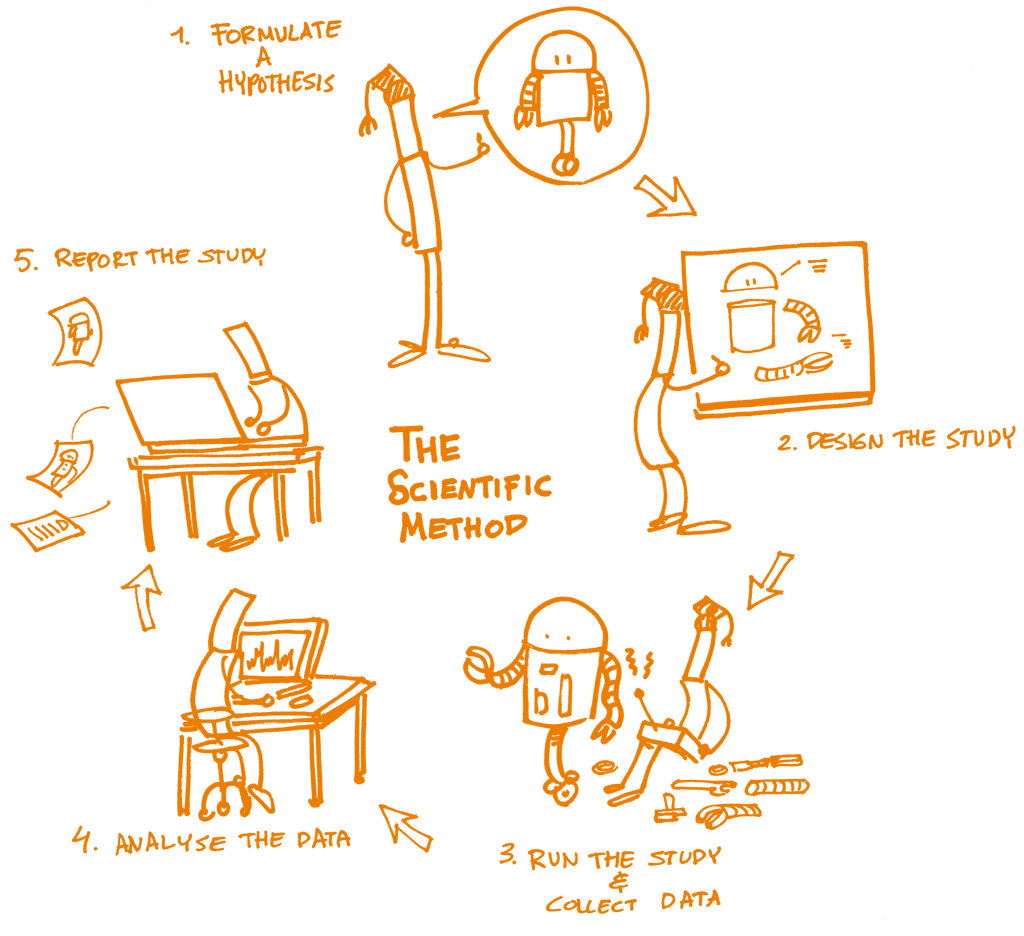
Data science has emerged as a critical field, driving insights and innovations across various industries. However, the challenge of reproducibility remains a significant hurdle for data scientists. In this context, Pachyderm offers a powerful solution that enables users to create reproducible data science workflows. With its unique approach to data versioning and pipeline management, Pachyderm empowers data scientists to ensure that their analyses can be replicated and validated by anyone at any time. This article delves into the essentials of reproducible data science with Pachyderm, highlighting the advantages and features available in a free PDF format.
Understanding the importance of reproducibility in data science is crucial. When data scientists share their findings, they must ensure that others can replicate their results using the same data and methods. This article will explore how Pachyderm facilitates this process, offering various tools and features that streamline the creation of reproducible workflows. By examining the principles of reproducible data science and Pachyderm's capabilities, readers will discover how to enhance their data science projects.
In this guide, we will also provide insights into accessing a free PDF that outlines the fundamentals of reproducible data science with Pachyderm. This resource will serve as a valuable reference for both novice and experienced data scientists, equipping them with the knowledge and tools needed to implement best practices in their projects. So, whether you're just starting in the field or looking to refine your skills, this article will be an essential resource for mastering reproducible data science.
What is Pachyderm and How Does It Enhance Reproducibility?
Pachyderm is an open-source data science platform designed to facilitate reproducible data science workflows. It integrates version control for data and pipelines, allowing data scientists to manage and track changes over time. This feature is crucial for ensuring that analyses can be duplicated, modified, and verified by others.
Why is Reproducibility Important in Data Science?
Reproducibility is a cornerstone of scientific research and data analysis. It allows researchers to validate findings, compare results, and build upon previous work. In data science, reproducibility means that others can replicate experiments and analyses using the same datasets and methodologies. This leads to greater trust in results and encourages collaboration among data scientists.
How Does Pachyderm Ensure Data Versioning?
Pachyderm employs a unique data versioning system that tracks changes made to datasets over time. This means that data scientists can easily revert to previous versions, compare different iterations, and maintain a clear history of their data. This level of control is essential for reproducibility, as it allows researchers to document their processes meticulously.
How Can You Access the Free PDF on Reproducible Data Science with Pachyderm?
To access the free PDF guide on reproducible data science with Pachyderm, simply visit the official Pachyderm website or relevant repositories where educational resources are provided. The PDF offers a comprehensive overview of the platform's features and best practices for creating reproducible data science workflows.
What Key Features of Pachyderm Support Reproducibility?
- Data Versioning: Track changes to datasets and revert to previous versions as needed.
- Pipeline Management: Create and manage complex data processing pipelines with ease.
- Collaboration Tools: Facilitate teamwork by allowing multiple users to work on the same project simultaneously.
- Environment Management: Ensure that analyses run in consistent environments, reducing variability in results.
How Can Beginners Get Started with Pachyderm?
For those new to Pachyderm, getting started is straightforward. The official documentation provides step-by-step instructions on installation and basic usage. Additionally, the free PDF on reproducible data science with Pachyderm serves as an excellent introductory resource. Beginners can benefit from tutorials, community forums, and webinars that offer practical insights into using the platform effectively.
What Are the Best Practices for Implementing Reproducible Data Science?
Implementing reproducible data science requires careful planning and adherence to best practices. Here are some key guidelines to follow:
- Document Your Workflow: Keep detailed records of every step taken during data analysis, including data sources, preprocessing steps, and modeling choices.
- Use Version Control: Leverage Pachyderm's version control features to manage changes to datasets and code.
- Share Your Work: Make your analyses accessible to others by sharing notebooks, code, and documentation.
- Test Your Work: Regularly validate your analyses by running tests and comparing results with expected outcomes.
Conclusion: Why You Should Embrace Reproducible Data Science with Pachyderm
In conclusion, reproducible data science is essential for ensuring the credibility and reliability of data analyses. Pachyderm stands out as a robust platform that simplifies the process of creating reproducible workflows. By utilizing its features and following best practices, data scientists can enhance their work and contribute to a culture of transparency and collaboration in the field. Don't forget to download the free PDF on reproducible data science with Pachyderm to kickstart your journey toward mastering this vital aspect of data science.