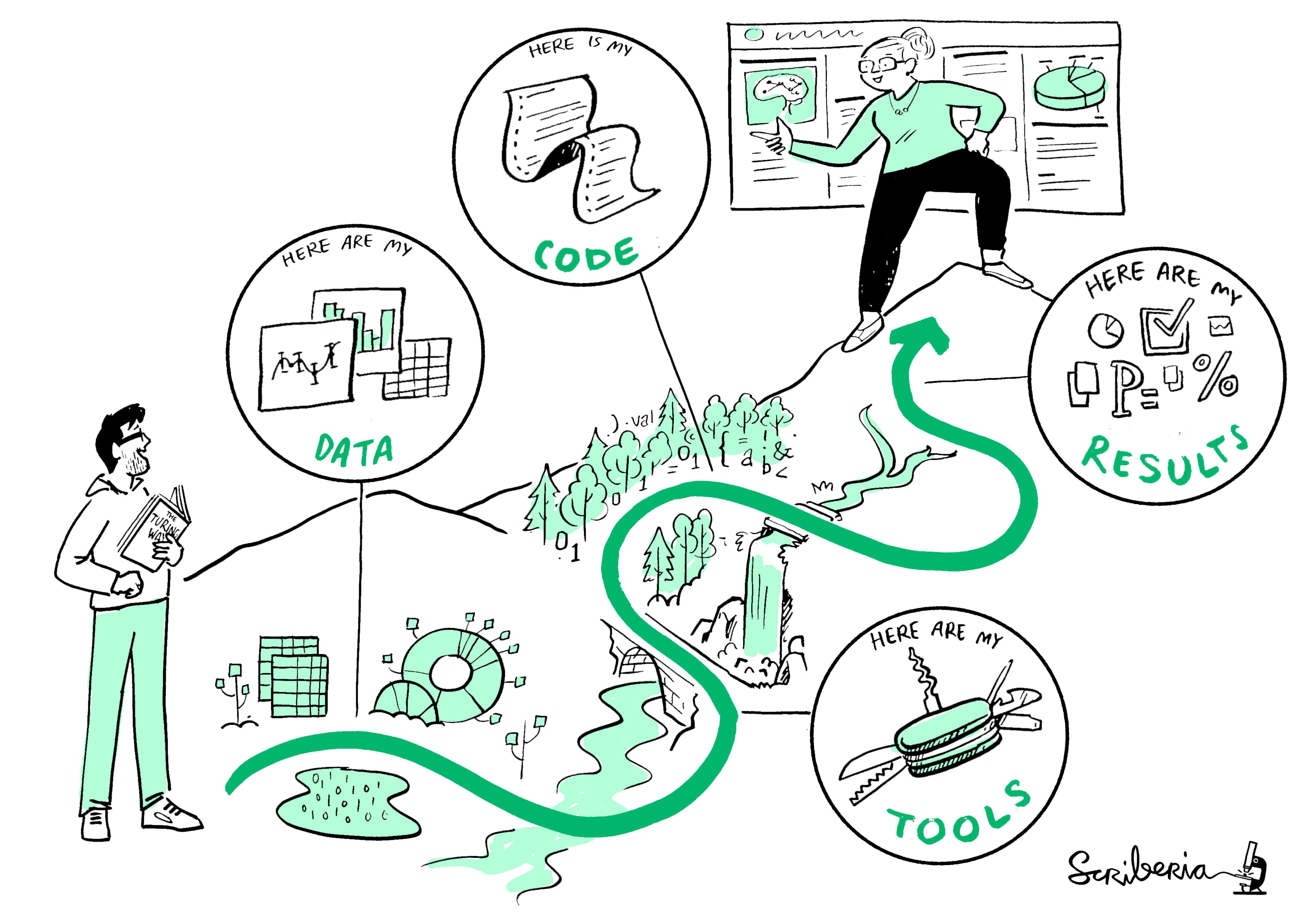
In the realm of data science, reproducibility is a crucial aspect that ensures the integrity and reliability of results. The emergence of tools like Pachyderm has transformed how data scientists approach their work, making it easier to create reproducible data pipelines that can be shared and utilized across various platforms. This innovative technology not only streamlines the data science workflow but also enhances collaboration among teams, fostering a culture of transparency and trust in data-driven decisions.
The rise of the data-driven economy has underscored the need for robust methodologies that allow for consistent results. With the increasing complexity of data science projects, having a systematic way to document and replicate analyses becomes vital. Pachyderm empowers data scientists to maintain version control over their data and workflows, enabling them to roll back to previous versions or experiment with new algorithms without fear of losing valuable insights. This level of control is essential for organizations that depend on accurate and repeatable outcomes.
For those eager to dive deeper into the world of reproducible data science, the "Reproducible Data Science with Pachyderm" PDF is an invaluable resource. It provides comprehensive guidance on leveraging Pachyderm's capabilities to build efficient and scalable data pipelines. Moreover, accessing this PDF for free opens doors for aspiring data scientists and seasoned professionals alike to enhance their skills and knowledge in this pivotal area of data science.
What is Pachyderm?
Pachyderm is an open-source data versioning tool that focuses on enabling reproducible data science. It allows teams to manage their data and data pipelines in a way that ensures that every step of the analysis can be traced back and replicated. This not only helps in validating results but also in maintaining the integrity of the data used throughout the analysis process.
How Does Pachyderm Ensure Reproducibility?
Pachyderm achieves reproducibility through several key features:
- Version Control: Pachyderm uses Git-like versioning for data sets, allowing users to track changes and revert to previous versions as needed.
- Data Pipelines: Users can create data pipelines that define how data is processed, ensuring that analyses can be consistently replicated.
- Containerization: Utilizing Docker containers, Pachyderm isolates different stages of data processing, ensuring that changes in one part of the pipeline do not affect others.
- Metadata Tracking: Pachyderm automatically tracks metadata associated with data and processes, providing a complete history of data transformations.
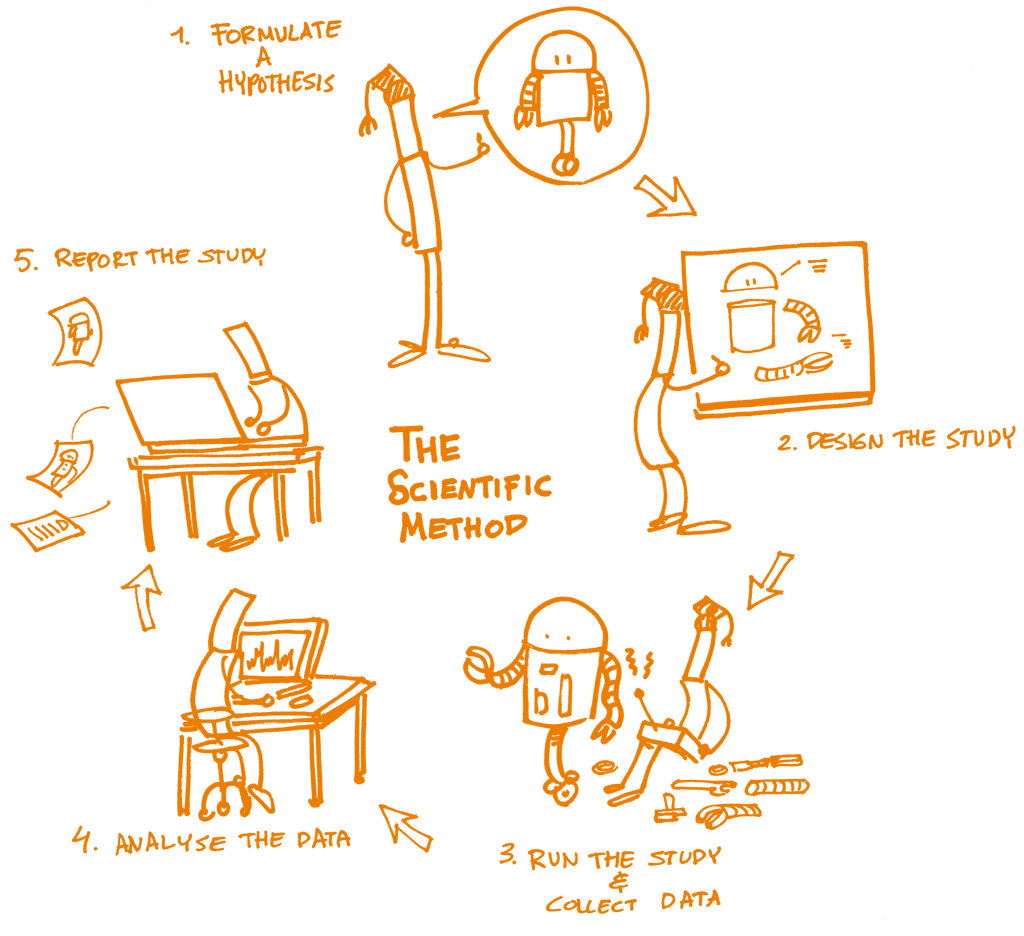
Why is Reproducibility Important in Data Science?
Reproducibility is essential in data science for several reasons:
- Validation of Results: It allows researchers and analysts to confirm findings by replicating experiments.
- Collaboration: Teams can share their work confidently, knowing others can reproduce and build upon it.
- Transparency: Stakeholders can trust the results when they know the processes can be independently verified.
- Efficiency: It reduces time spent on troubleshooting and redoing analyses, streamlining workflows.
Where Can You Find the "Reproducible Data Science with Pachyderm" PDF?
The "Reproducible Data Science with Pachyderm" PDF is available for free download on various platforms dedicated to data science education. Websites like GitHub, academic resource portals, and data science blogs often host such PDFs. It's important to ensure that the source is credible to obtain the most accurate and helpful information.
What Can You Expect to Learn from the PDF?
The PDF covers a wide range of topics, including:
- An introduction to Pachyderm and its architecture
- Step-by-step guides on setting up data pipelines
- Best practices for ensuring reproducibility in data science projects
- Case studies showcasing successful implementations of Pachyderm
How Can You Apply the Knowledge Gained from the PDF?
After downloading and studying the "Reproducible Data Science with Pachyderm" PDF, you can apply the knowledge in various ways:
- Implement Pachyderm in your current data science projects to improve reproducibility.
- Share the insights with your team to foster a collaborative approach to data analysis.
- Experiment with different data pipelines to understand their impact on your results.
- Contribute to open-source projects that utilize Pachyderm, enhancing your skills further.
Conclusion: Embracing Reproducibility with Pachyderm
The world of data science is ever-evolving, and with tools like Pachyderm, professionals can ensure their analyses are reproducible and reliable. By embracing the principles outlined in the "Reproducible Data Science with Pachyderm" PDF, data scientists can not only enhance their own workflows but also contribute to a culture of transparency and collaboration within their organizations. Don't miss the opportunity to download this valuable resource and take your data science skills to the next level!
In summary, accessing the "Reproducible Data Science with Pachyderm PDF free download" is a fantastic step towards mastering reproducible data science. With Pachyderm’s capabilities, you can unlock new potentials in your data analyses while ensuring trust and consistency in your results.
![Reproducible Data Science with Pachyderm [Book]](https://i2.wp.com/www.oreilly.com/library/cover/9781801074483/1200w630h/)

