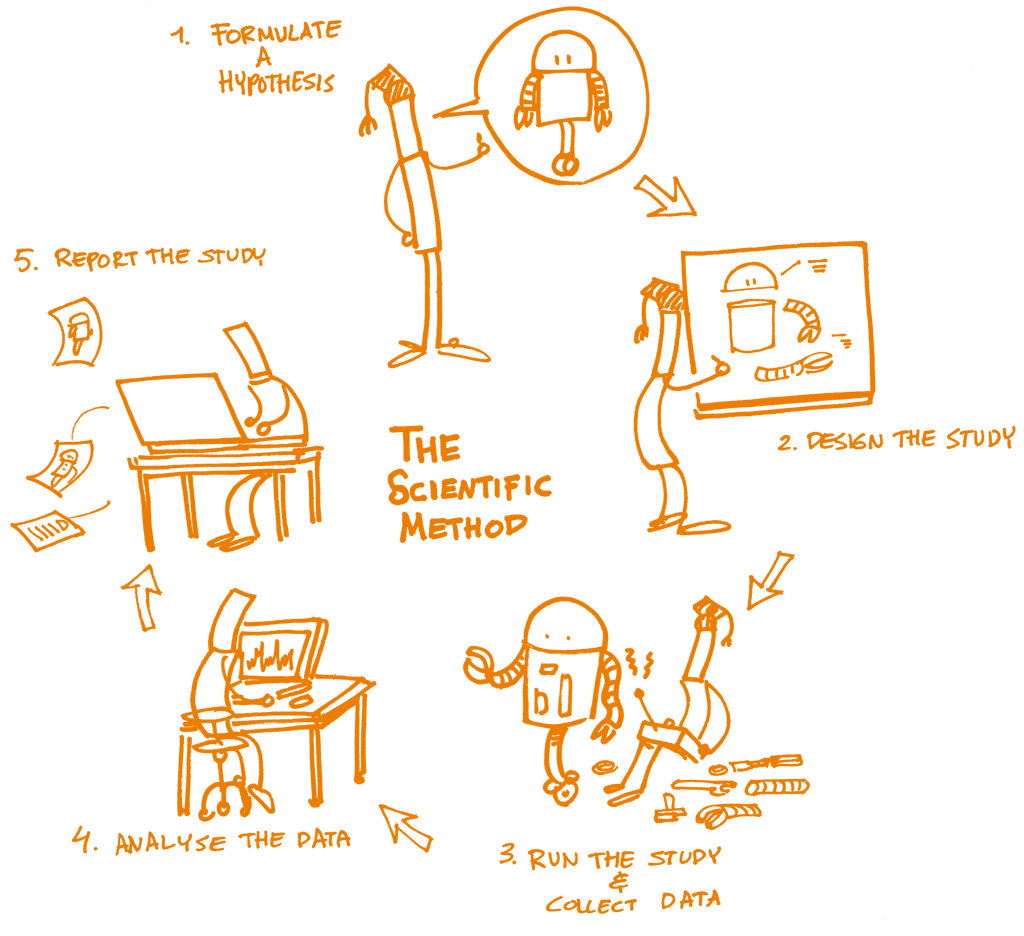
In the ever-evolving landscape of data science, ensuring reproducibility is paramount for researchers, organizations, and data enthusiasts alike. The ability to consistently replicate results is not only a hallmark of scientific integrity but also a crucial factor in building trust in data-driven decisions. This is where Pachyderm steps in, offering a robust framework that empowers users to build reproducible data science workflows. By embracing Pachyderm, data scientists can streamline their processes, making it easier to share insights and collaborate effectively.
Moreover, Pachyderm's unique version control system for data and metadata allows teams to track changes, manage dependencies, and ensure that every step of their analysis is documented and reproducible. As the demand for transparency in data science grows, understanding how to leverage tools like Pachyderm becomes essential. This article explores the principles of reproducible data science with Pachyderm, guiding you through the capabilities that make it a game-changer in the field.
As we delve into the world of reproducible data science with Pachyderm, we'll address common questions, share practical insights, and illustrate how this powerful tool can transform your data workflows. Whether you're a seasoned data scientist or just starting your journey, the information presented here will illuminate the path to achieving reproducibility and reliability in your analyses.
What is Pachyderm and How Does it Work?
Pachyderm is an open-source data versioning and data pipeline tool designed to facilitate reproducible data science workflows. It provides a platform where data scientists can build, manage, and share their data pipelines seamlessly. At its core, Pachyderm leverages the power of containers and version control, allowing users to track every change made to their datasets, similar to how Git operates for code.
Why is Reproducibility Important in Data Science?
Reproducibility in data science is crucial for several reasons:
- Validation of Results: Ensures that findings can be independently verified by others.
- Collaboration: Facilitates teamwork by allowing others to replicate and build upon your work.
- Transparency: Increases trust in your methodologies and findings among stakeholders.
- Efficiency: Saves time by allowing users to recreate analyses without starting from scratch.
How Does Pachyderm Facilitate Reproducible Data Science?
Pachyderm enhances reproducibility through its unique features:
- Data Versioning: Every dataset is versioned, allowing users to revert to previous states effortlessly.
- Pipeline Management: Users can create data pipelines that define the transformations applied to data, ensuring a repeatable process.
- Containerization: Integrates with Docker, ensuring that the environment used for data analysis is consistent and replicable.
- Git-like Approach: Users can track changes, manage branches, and collaborate on complex datasets just like they would with code.
Can Pachyderm Be Integrated with Other Tools?
Yes, Pachyderm is designed to work seamlessly with various data science tools and technologies. Some popular integrations include:
- Jupyter Notebooks: For interactive data exploration and analysis.
- TensorFlow: For building and deploying machine learning models.
- Apache Spark: For large-scale data processing and analytics.
- Data Visualization Libraries: Such as Matplotlib and Seaborn for presenting insights effectively.
What are the Challenges of Achieving Reproducibility?
Despite the advantages of reproducibility, several challenges remain:
- Environment Differences: Variations in software versions and configurations can lead to discrepancies in results.
- Data Management: Handling large datasets can be cumbersome without proper versioning.
- Documentation: Inadequate documentation can hinder others from understanding and replicating your work.
How Can You Get Started with Pachyderm?
To begin your journey with Pachyderm, follow these steps:
- Install Pachyderm: Follow the installation guide available on the official Pachyderm website.
- Create a Data Repository: Set up a repository to store your datasets and version them.
- Build Your First Pipeline: Define a pipeline that processes your data and produces outputs.
- Collaborate: Share your work with colleagues and encourage them to contribute.
What are the Future Trends of Reproducible Data Science?
The future of reproducible data science looks promising, with trends such as:
- Increased Automation: Tools like Pachyderm will continue to evolve, offering more automated features for data management.
- Enhanced Collaboration: Greater emphasis on sharing insights and methodologies across teams and organizations.
- Focus on Ethics: A growing awareness of ethical considerations in data science, driving the demand for reproducibility.
Conclusion: Embracing Reproducibility with Pachyderm
As organizations continue to harness the power of data, the need for reproducible data science practices becomes increasingly critical. Pachyderm stands out as a tool that not only facilitates this process but also empowers data scientists to create reliable, transparent, and shareable workflows. By integrating Pachyderm into your data science toolkit, you can enhance the reproducibility of your analyses and contribute to a culture of trust and collaboration in the data community. With practical steps to get started and an eye on future trends, the journey to mastering reproducible data science with Pachyderm is within reach.